Abridging clinical conversations using Python
At Abridge, our mission is to bring context and understanding to every medical conversation so people can stay on top of their health. We leverage groundbreaking machine learning (ML) research to help people focus on the most important details from their health conversations. Python powers major aspects of Abridge’s ML lifecycle, including data annotation, research and experimentation, and ML model deployment to production.
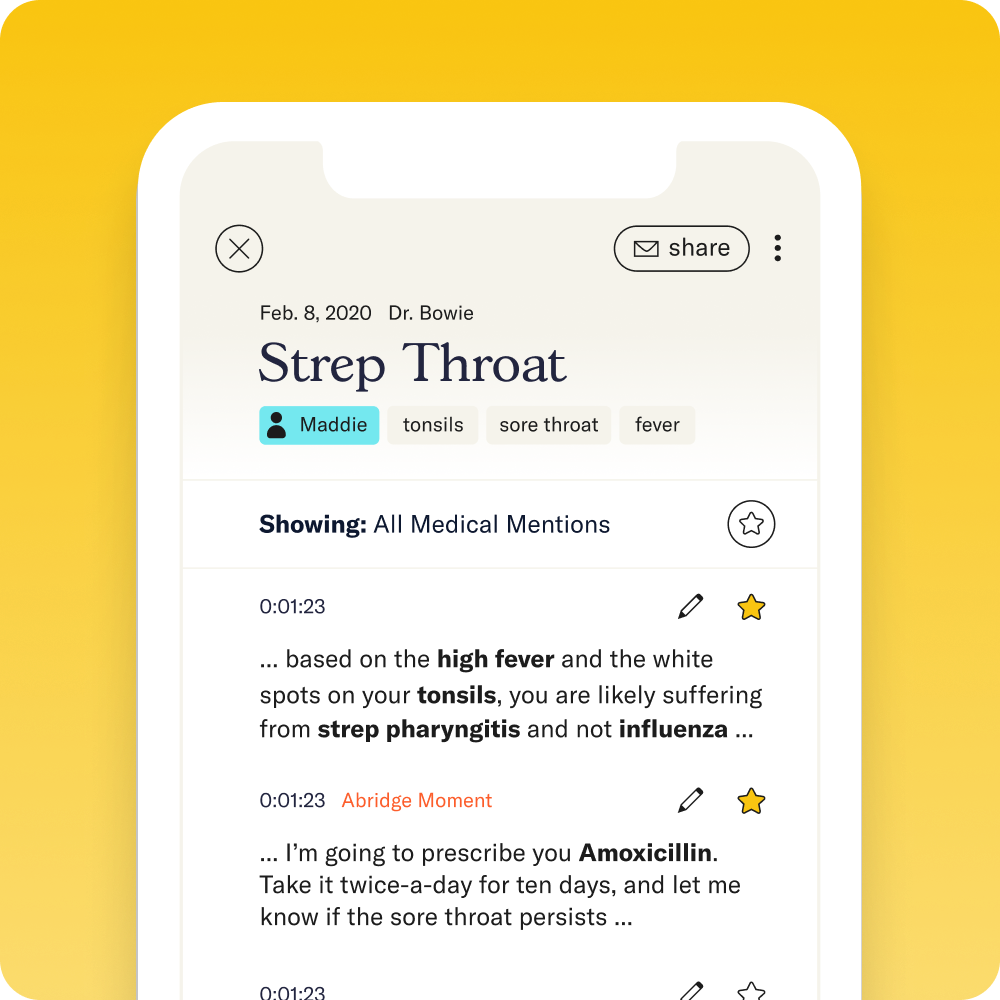
A screenshot of our mobile application showcasing our clinical concept extraction module (as bolded words) and a plan classifier (as Abridge Moment). Both are powered in part by Python.
Machine Learning
Dialogue modeling, natural language understanding, information extraction, and summarization are some of the active research areas that we pursue at Abridge. Our research is powered by one of the biggest corpora of real, de-identified, and fully consented health conversations. We’ve diligently annotated the data, using guidelines and templates devised in collaboration with clinicians and researchers. Google Sheets’ Python API has allowed us to scale the creation of annotation templates, allocate files appropriately to annotators, and efficiently manage the quality control process — all without having to build any new web or mobile applications.
Jupyter Notebook, a spin-off project from the IPython project, allows us to clean data, build and train machine learning models, and assess the performance of models in an integrated environment. For example, we used Jupyter to build, test, and visualize the models featured in some of our recently published work — including a medication regimen extraction pipeline that can automatically extract medication, dosage, and frequency from medical conversations and an Automatic Speech Recognition (ASR) correction system that can improve the transcript quality of general purpose ASR systems.
We use a wide variety of python packages and libraries: Scikit-learn, PyTorch, AllenNLP, and Tensorflow for machine learning; NLTK, and Spacy for text processing; and Numpy, Pandas, Matplotlib, Seaborn for data exploration. In addition, we use Django to build dashboards to visualize data and qualitatively assess our ML models. All of our production ML services are built using the python frameworks, Falcon and Gunicorn. Usage of python makes the transition from ML research to production services easy and enables us to serve our users reliably.
Python is a crucial part of the development process at Abridge. In addition to the above-mentioned instances, we also use Python widely in conjunction with several Google Cloud Platform (GCP) services and to set up other monitoring and debugging tools. We are thankful to the Python community for building amazing tools that enable us to provide magical, patient-centered experiences at Abridge.
About the authors
Nimshi Venkat is a Machine Learning Researcher, and Sandeep Konam is the co-founder/CTO at Abridge. If you are interested in joining us, please check out https://www.abridge.com/team