
How HyperFinity Is Streamlining Its Serverless Architecture with Snowflake's Snowpark for Python
HyperFinity is a decision science SaaS platform. Through machine learning and AI, embedded analytics, and data visualization, HyperFinity enables nontechnical users to make data-led decisions and create simple outputs to power downstream systems, such as CRM, ERP, or content management systems. This enables organizations to quickly make ML-powered decisions across multiple areas, from smarter supply chain to optimized pricing.
Snowflake sits at the core of HyperFinity’s data-intensive platform. In addition to the extensive data type support such as variant data type for semi-structured data, other features such as Snowflake REST API and Zero-Copy Cloning serve as valuable tools in the platform’s serverless architecture. Snowflake’s Secure Data Sharing also streamlines the ELT processes and simplifies the integration of the HyperFinity platform and its outputs with our customers who are already using Snowflake.
Challenge: Separate infrastructure for separate programming languages
While HyperFinity’s platform is built for nontechnical users to easily apply machine learning and AI at the click of a button, all of the functionality for the data processing that is needed is developed by a data science-focused team, whose primary coding languages are SQL and Python. Snowflake handled all of our SQL development and processing, but in order to construct a serverless compute engine for our Python code, our team had to set up a new set of cloud infrastructure on AWS, which entailed stitching together multiple compute services such as Amazon EC2 and AWS Lambda. This had several downsides such as having to move the data outside of Snowflake’s governance boundary for processing, maintaining additional infrastructure, and writing additional code to handle the data structures changing between services.
When we saw Python support for Snowpark announced, we got very excited about the possibilities it would enable for us, and we were very lucky to take part in the private preview.
Streamlining our architecture with Snowpark for Python
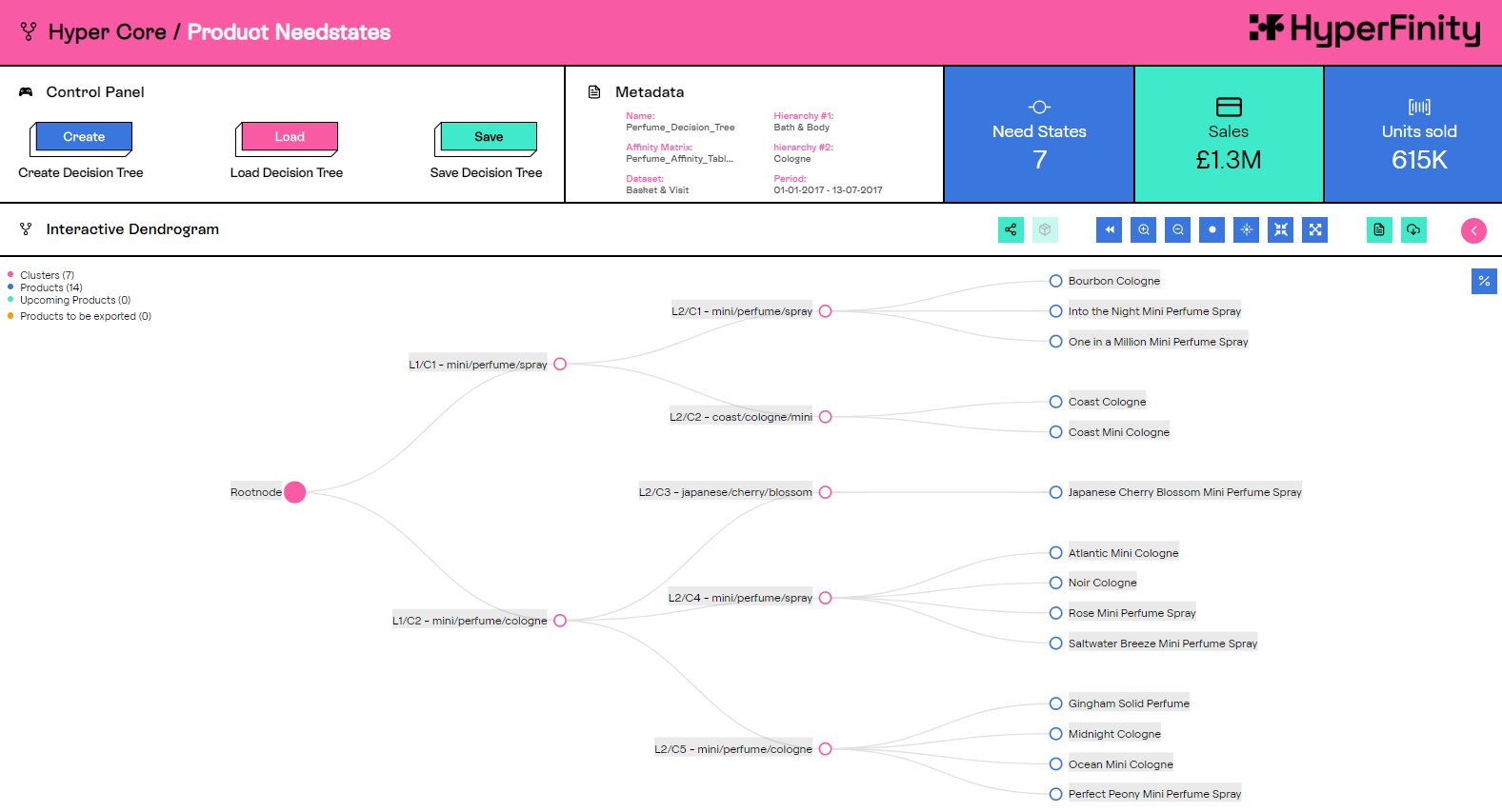
One of the benefits of Python is its rich ecosystem of open source packages and libraries, which we use extensively. For example, a core part of the platform is creating “Customer Needstates” for groups of products. This uses a technique called hierarchical clustering to create a customer decision tree, which represents the choices an individual makes to arrive at the product they purchase. Computing these Needstates requires matrix and array multiplication, which our team leverages in Snowpark using the Python libraries numpy and scipy. This type of calculation is much simpler to develop and implement in Snowflake through the use of Snowpark.
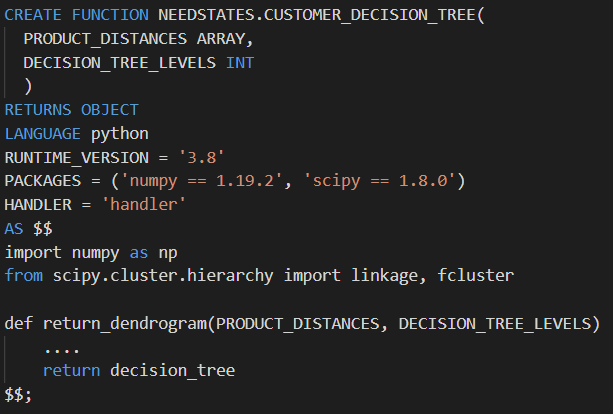
Previous cloud infrastructure for Python processing replaced by simple Snowpark code
Because the Snowpark for Python environment comes with 1,000+ pre-installed libraries through Snowflake’s partnership with Anaconda, we could easily move existing functions with minimal effort. Having the most popular libraries available removes another layer of administration from the development process, and with the integrated conda package manager there is no need to worry about dependency management. In case we need a custom library, Snowflake supports the ability to upload and import custom Python code.
We’re also able to blend SQL and Python logic together in a way that would previously have involved sending data back and forth between multiple tools, and our team has also been able to gain increased performance through parallelizing our processing. Using this blend of SQL and Python we can run logic written in Python on multiple rows of SQL concurrently, turning what was previously a looping operation into a parallel process. For example, running our clustering solutions at five different depths takes the same time as running at one depth.
“Snowpark enables us to accelerate development while reducing costs associated with data movement and running separate environments for SQL and Python.”
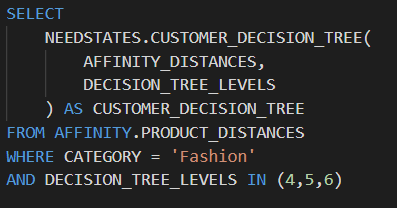
Running a Python function as part of a SQL statement in Snowflake, including parallel processing
Moving our Python processes to Snowpark has removed unnecessary complexity from our architecture and simplified our development by removing all the extra code that handled data structures changing between services. Now our team can develop, test, and deploy their Python code within the same environment the data is stored, leveraging the power of the Snowflake platform, and in their preferred development language.
HyperFinity is software designed to make decision-making simple, using powerful data science and advanced analytics techniques. Snowflake, and now Snowpark, are major pieces of HyperFinity’s architecture, and we’re very pleased with the performance and stability that Snowflake brings to the software as well as the new features being released by Snowflake to make working with it even more powerful.
As a startup, building our application on top of Snowflake has simplified our infrastructure and development process, and accelerated the software’s path to market.